
瑞幸咖啡背后的芯片,藏不住了。
当你走进瑞幸咖啡店,点一杯生椰拿铁的扫数经过,举例下单、出杯、核销、取餐……这一切的背后其实都有一对“眼睛”在盯着。
在看什么?
它要及时识别订单、判断制作节律、校验物料景况、监控设立运行,还要把数据同步回总部,用于品控、调养和运营决策。
这就是藏在瑞幸咖啡背后大批的旯旮侧AI,它们有一个共性,那即是算力必须就近部署,反应必须迷漫快,踏实性必须迷漫强,本钱还要可控。
芯片,成了其中关键中的关键。
就在今天,瑞幸背后芯片的图穷匕首见终于浮出了水面——
来自一家刚刚完成上市不久的国产通用GPU公司,天数智芯。
前脚刚刚敲完钟,时隔仅半个月时辰,天数智芯便又相接发布了四款边端算力家具,彤央系列。
而且不仅仅发布的算作,像瑞幸仍是在用的边端算力,恰是彤央。
那么这个系列的家具到底实力几何,咱们持续往下看。
相接发布四款新品先来看名字。
彤央之名,源自商周青铜器铭文,但在天数智芯的里面,彤央有着别样的寓意:
“彤”指向高能效诡计才调,“央”则意味着在边端场景中承担核默算力重要的扮装。
换言之,这是一个为真实业务现场而生的算力系列。
彤央系列的首发威望,共包括四款家具:TY1000、TY1100,以及定位算力结尾的TY1100_NX和TY1200。
先看彤央TY1000。
这是一个圭表699Pin接口的模组,尺寸惟有口袋大小,但在这个方寸之间,天数塞进了近200T的粘稠算力。
在本体测试中,无论是典型的CV任务,如故NLP推理,甚而是对参数界限达到32B的DeepSeek-R1模子进行推理,以及具身智能VLA模子及宇宙模子等场景,TY1000在多格式的上都展现出不弱于主流海外决策的弘扬。

在天数智芯长远的测试数据中,TY1000在多类负载下的玄虚结尾,跨越了英伟达AGX Orin所对应的典型配置。
固然这并不虞味着全面替代,但至少诠释了一件事:在边端通用推理这个维度,国产通用GPU仍是具备了正面临比的才调。
其次是彤央TY1100。
这款家具在架构上进行了进一步升级,弃取了12核ARM v9架构CPU,并在系统级算力供给上愈加充沛。
它面向的是对通用诡计和AI推理都有较高条目的复杂场景,比如多传感器和会、旯旮数据预措置、及时决策等。
若是说TY1000更偏向算力中枢,那么TY1100则更像是一块竣工的旯旮诡计底座。
接下来,是针对对显存容量和性价比愈加明锐用户的TY1100_NX。
更大的显存配置,使其在多模子并行、长序列推理等场景中具备更高的踏实性,同期保管了即插即用的部署格式,裁汰了系统集成门槛。
终末,即是彤央TY1200,则被天数智芯界说为算力结尾。
它的算力规格擢升到了300 TOPS,更蹙迫的是,它是面向结尾形态的举座决策。这类家具的标的用户,并不仅仅算法工程师,还包括但愿径直把AI才调装进设立的行业客户。
从家具组合上看,彤央系列并莫得走单点极致道路,而是刻意拉开了算力、形态和价钱区间,狡饰从算力模组到结尾的不同部署需求。

但天数智芯并莫得把重心只放在芯片的参数上。
在生态层面,彤央系列在接口和形态上竣事了与主流家具的Pin-to-Pin兼容,大幅裁汰了客户从既有决策挪动的本钱。
这少量,关于仍是有熟谙系统的工业和生意客户来说,简直是“是否无礼尝试”的分水岭。
更蹙迫的是,这些家具并不是为了发布而发布。
在机器东说念主领域,彤央与格蓝若机器东说念主互助参加企业本体应用场景;在工业侧,比依电器等制造企业正在用其进行设立智能化升级;在生意零卖场景中,快乐彩app下载瑞幸咖啡仅仅其中一个典型案例;而在交通领域,彤央系列也仍是参与到多个车路云一体化试点中。
当四个都备不同的行业场景,运诈欺用并吞套通用GPU算力底座时,一个更大的问题随之浮现:
天数智芯实在思作念的,究竟是什么?
天数智芯的“贪图”也泄露了若是只看彤央系列,很容易贯串为一家国产芯片公司思要最初补全云边端的业务疆域。
但从其通常于1月26日公开长远的架构道路图来看,事情彰着莫得这样浅薄,在其业务大本营的云霄场景,天数有更贪图勃勃的标的。
天数智芯并不自大于国产替代这个阶段性标的。在屡次公开时局中,它都明确提到,我方的恒久标的是对标乃至超过英伟达这样的行业标杆。
为此,天数智芯给出了一张明确到年份的架构道路图。
2025年天数智芯推出的天数天枢架构,超过英伟达Hopper。据了解,这仍是不是揣摸打算,而是实践:该架构支捏从高精度科学诡计到AI精度诡计,AI芯片在实行谨防力机制联系诡计时,算力的本体灵验利用结尾达到90%及以上。
而测试数据显示,天数天枢架构结尾较刻下行业平均水平擢升60%,在DeepSeek V3场景平均比Hopper架构高约20%性能。
到2026年,天数天璇架构,新增ixFP4精度支捏,对标Blackwell;天数天玑架构,竣事全场景AI与加快诡计狡饰,超过Blackwell。
而在2027年,天数智芯揣摸打算中的天权架构,则径直指向对Rubin架构的全面超过,重心融入更多精度支捏与转变想象。
解救这条道路图的背后,还有一整套底层本领才调。
包括TPC Broadcast、Instruction Co-Exec、Dynamic Warp Scheduling在内的多项本领,组成了天数智芯在请示级并行、资源调养和算力利用率上的中枢上风。
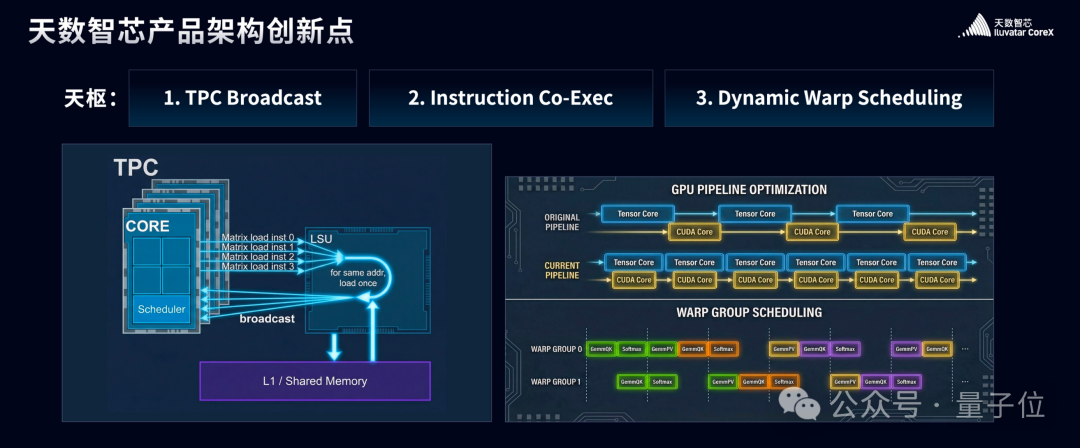
这些才调,决定了它是否果真具备在通用GPU赛说念恒久演进的可能性。
那么,天数智芯是否果真有这样的实力?
一个直不雅的判断格式,是看通用性。
逼迫当今,天数智芯的通用GPU仍是踏实运行400余种主流模子,而况强调Day 0适配才调;以DeepSeek为例,其在天数智芯平台上的适配和推理,仍是成为客户本体部署的一部分。
第二个维度,是生意化落地。
笔据其公开长远的数据,天数智芯累计委派的芯片数目仍是跨越5.2万片,办事客户跨越300家。
在本体应用中,互联网AI客服的算力本钱被压缩了一半,而单机性能翻倍;金融行业的研报生成结尾擢升了约70%;在高条目的集群场景中,其千卡界限集群仍是竣事了跨越1000天的踏实运行。
{jz:field.toptypename/}这些数据迷漫谨防,也迷漫具体。
尤其值得谨防的是,天数智芯在招股书中,对客户数目、量产发货界限、卡级毛利等中枢观念进行了相对竣工的长远。这种摊开来讲的格式,在刻下的国产芯片行业中并未几见。
也恰是在这少量上,天数智芯与不少大厂自研芯片或专用NPU道路拉开了差距。
它弃取了一条更难、也更慢的路——坚捏通用GPU道路,从架构、请示集、编译器到软件栈进行全栈自研。这意味着莫得盲区,也意味着每一步都必须我方趟夙昔。
终末,回到瑞幸的那杯咖啡。
当国产算力运行实在参加千行百业,参加门店、工场、说念路和设立,芯片不再仅仅发布会上的参数,果决是业务链条中不能或缺的一环。
从这个角度看,这次发布的意旨,概况并不单在于发布了四代架构图,和四款边端新品,而在于国产通用GPU,一边昂首,试图超过行业标杆,并以更大的贪图,尝试面向无东说念主区坑诰我方的旅途;一边垂头,以一种更逼近实践的格式,不休深入产业现场。
而这,可能才是天数智芯实在思诠释的事情。